TDRM
Smooth Reward Models with Temporal Difference for LLM RL and Inference
Process Reward Model + Online Temporal Difference Training
to Train Smooth and Strong Reward Models.
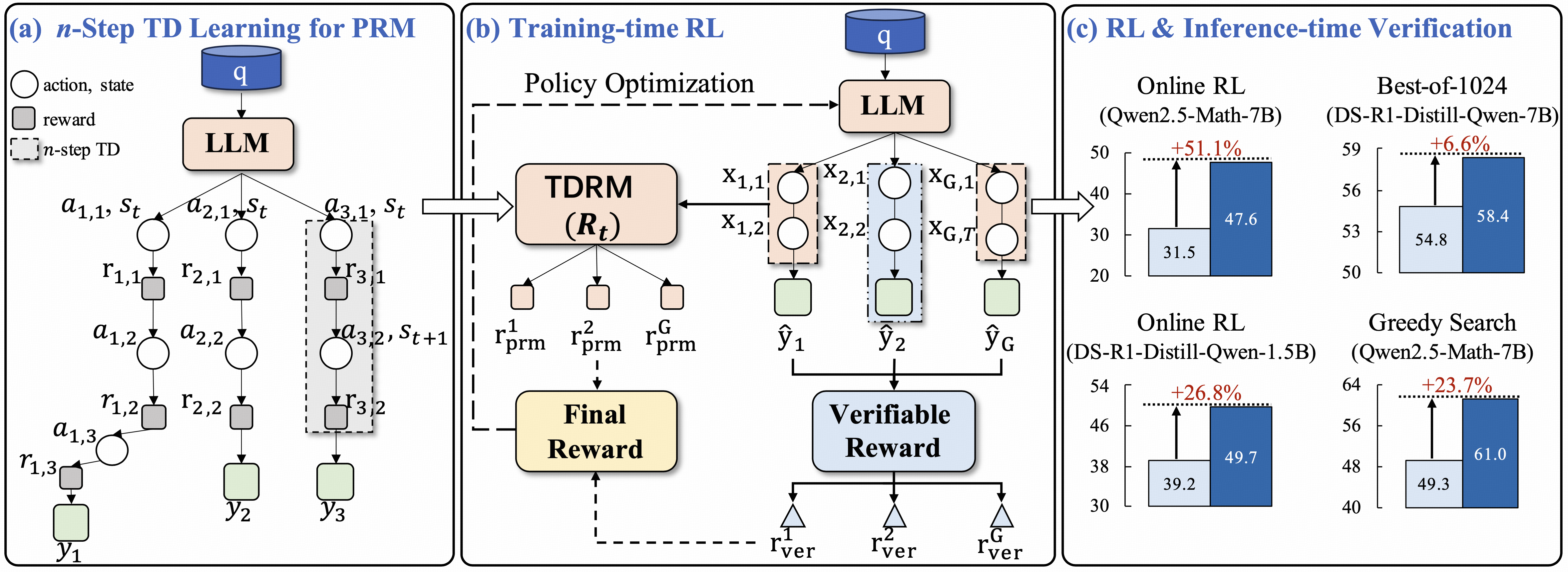
Overview of TDRM framework and improvement over baseline method.
Abstract
Reward models are central to both reinforcement learning (RL) with language models and inference-time verification. However, existing reward models often lack temporal consistency, leading to ineffective policy updates and unstable RL training. We introduce TDRM, a method for learning smoother and more reliable reward models by minimizing temporal differences (TD) for training-time reinforcement learning and inference-time verification. Experiments show that TD-trained process reward models (PRMs) improve performance across Best-of-$N$ (up to 6.6\%) and tree-search (up to 23.7\%) settings. When combined with Reinforcement Learning with Verifiable Rewards (RLVR), TD-trained PRMs lead to more data-efficient RL --- achieving comparable performance with just 2.5k data to what baseline methods require 50.1k data to attain --- and yield higher-quality language model policies in 8 model variants (5 series), e.g., Qwen2.5-(0.5B, 1,5B), GLM4-9B-0414, GLM-Z1-9B-0414, Qwen2.5-Math-(1.5B, 7B), and DeepSeek-R1-Distill-Qwen-(1.5B, 7B).
TDRM Algorithm
The TDRM framework aims to train a smooth reward model by leveraging trajectory-level optimization.
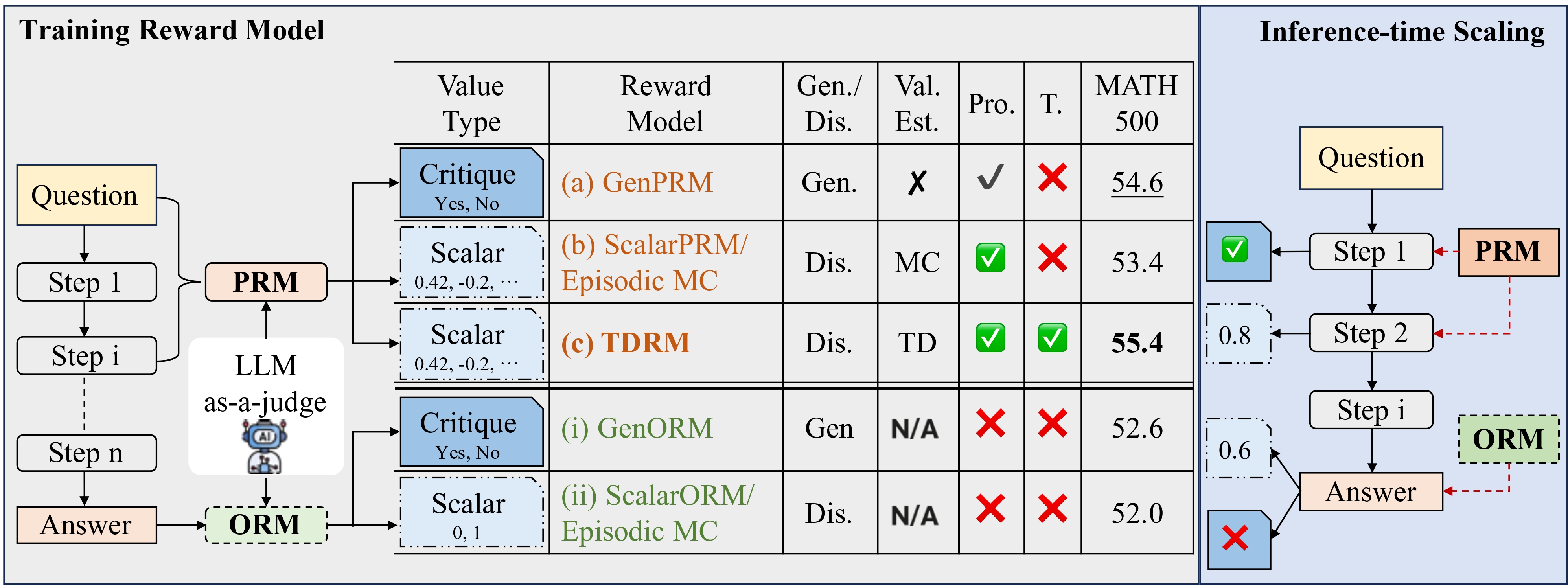
Training Smooth Reward Models
Bootstrapping Values from Upcoming States
Given a trajectory, the model bootstraps values from upcoming states to improve its current state estimates. For example for question:
What is the arithmetic mean of the integers from –4 through 5, inclusive? Express your answer as a decimal to the nearest tenth. In below, value estimate of state 1 is calculated by bootstrapping from state 2:
Applying TDRM to RL (Policy) Training
After obtaining smooth reward models, we can apply TDRM to reinforcement learning (RL) training. The key idea is to leverage the learned reward model to guide the policy optimization process by providing scalar rewards. In addition, we leverage both rewards from a RM and task-specific rules.
For example, when using GRPO as the RL algorithm:
Results
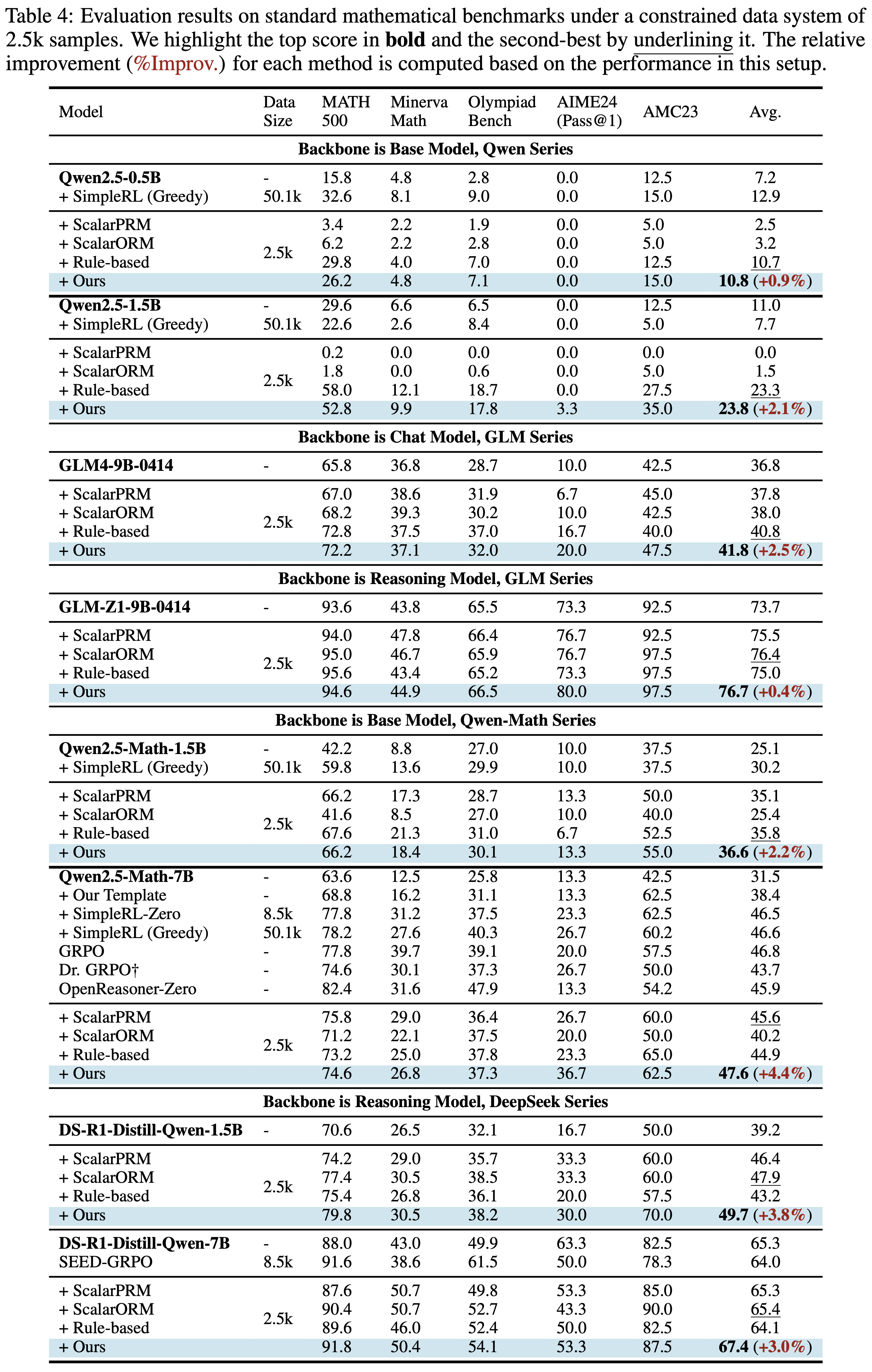
Result 1: Policy Training with TDRM
In below, we show the results of applying TDRM to policy training. Results are shown across different models, including Qwen2.5(-Math) series, GLM(-z1) series and DS-R1-Distill-Qwen series, showcasing their performance improvements with TDRM.
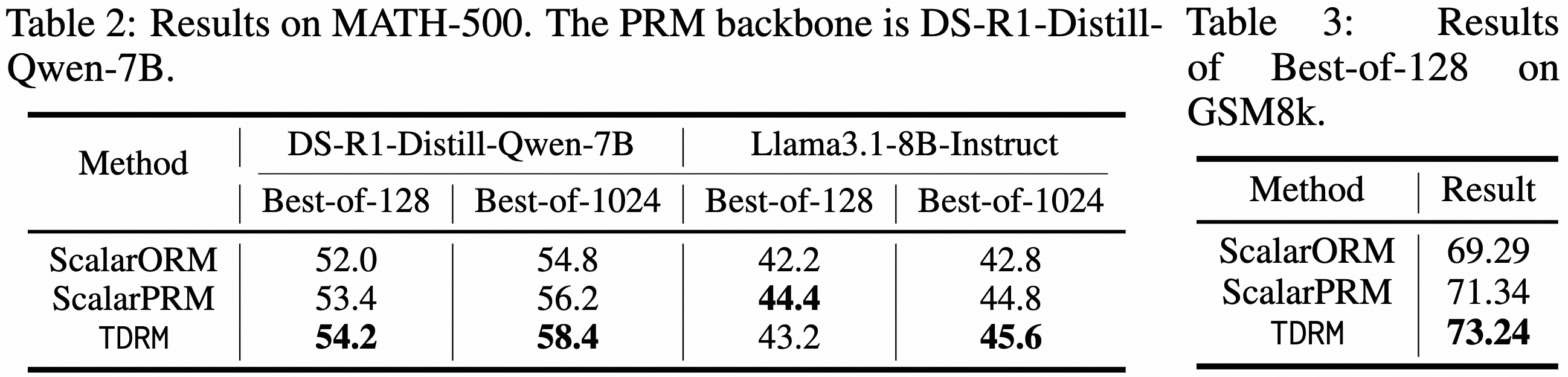
Result 2: Inference-Time Scaling
For Inference-time verification, we evaluate under two settings: Best-of-N sampling and Tree-search (greedy search).
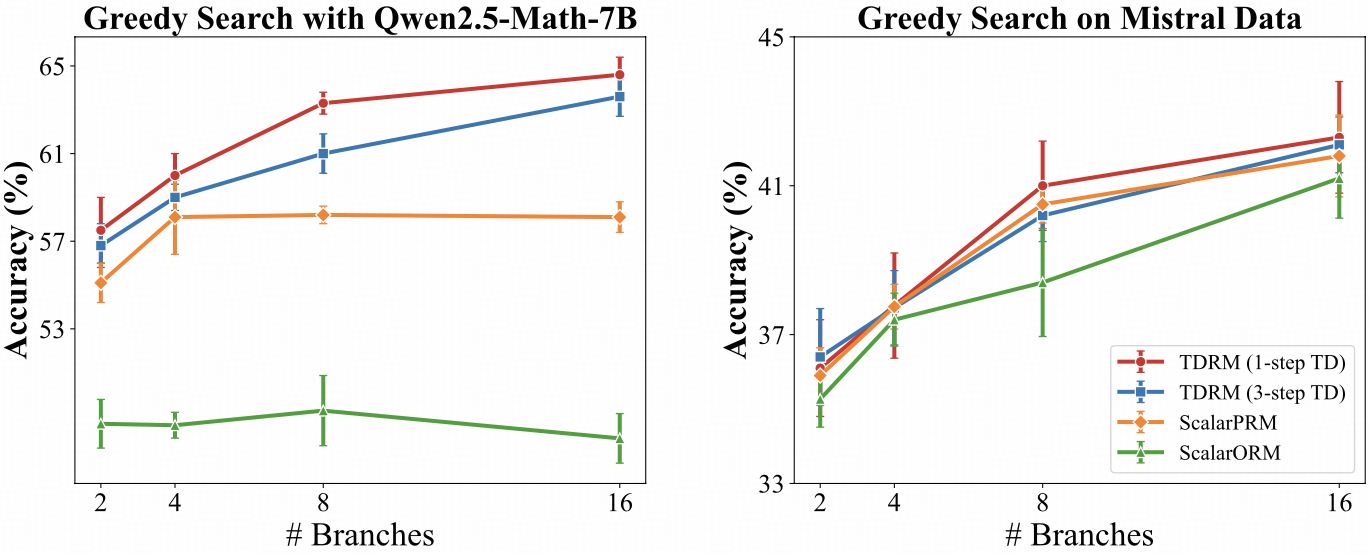
Analysis
Smoothness and Training Dynamics
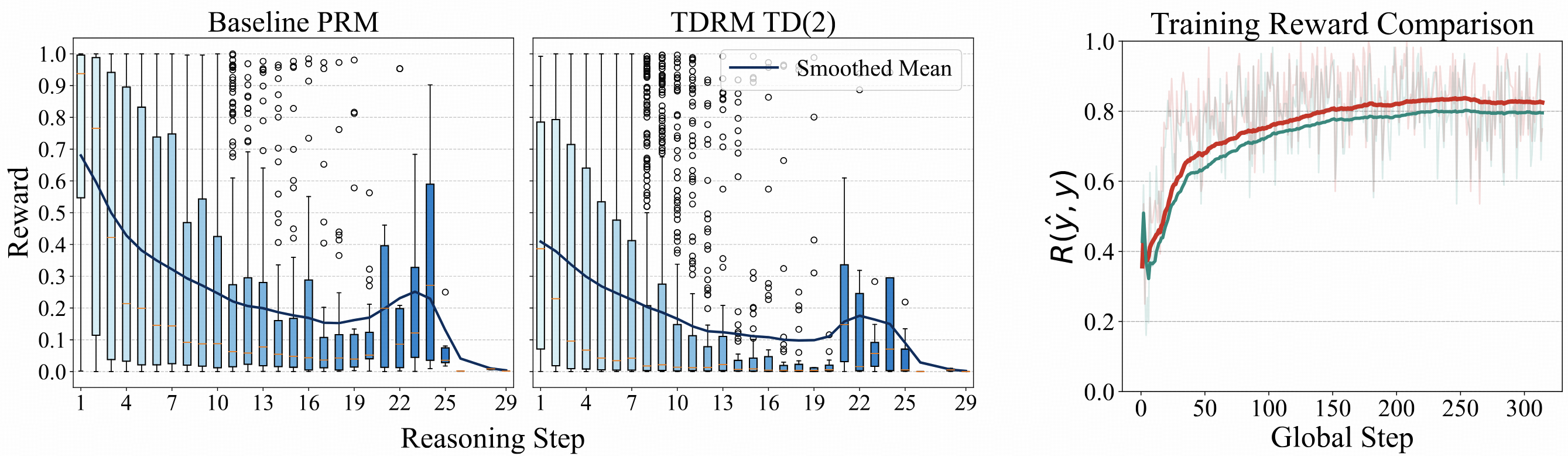
To demonstrate that the RMs trained with TDRM are smoother, we analyze their behavior across various dimensions.
First, we calculate a metric inspired by local Lipschitz continuity to quantify the smoothness of the RMs.
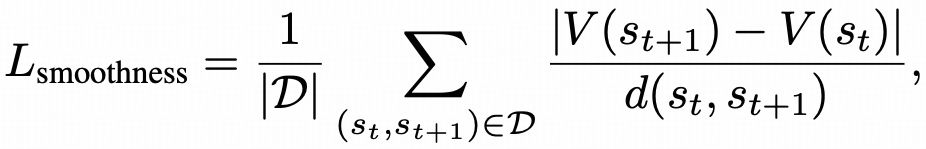
It is shown that TDRM (0.2741) is significantly smoother than the ScalarPRM (0.3331) according to this metric.
Furthermore, we analyze the smoothness by comparing TD error across steps, and TD error vs. absolute value difference.
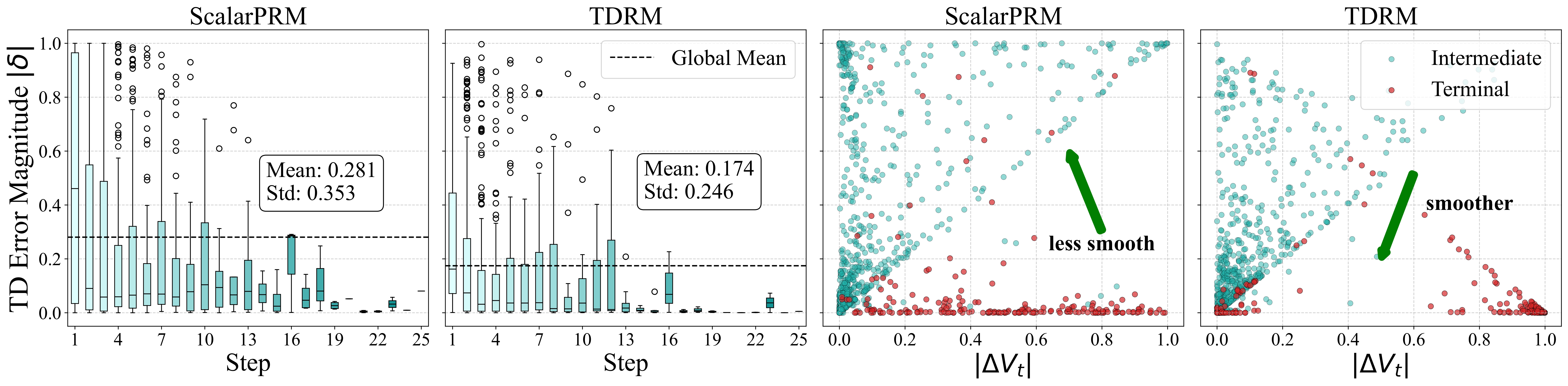
By examining the TD error across steps, we observe that TDRM consistently outperforms ScalarPRM, indicating its superior smoothness. And we also show the training dynamics of RL using TDRM, showcasing that TDRM can also improve the sample efficiency of RL training.